




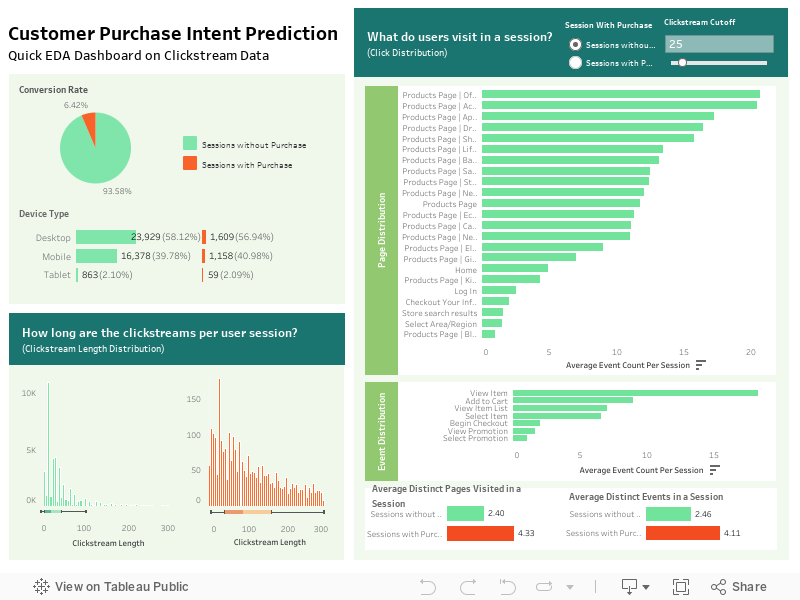
1. Imbalanced Dataset
The label distribution of sessions with and without purchase reveals that the dataset is highly imbalanced, with up to 93.5% of non-purchase sessions and only 6.4% purchase sessions. Therefore, it is necessary to balance the dataset before proceeding with model training.
2. Clickstream Lengths for Training
The clickstream length distribution showed a high degree of skewness in our data. Therefore, it is necessary to remove outliers and consider using median instead of mean when determining an appropriate clickstream length range for model training.
The distribution also showed that the clickstream lengths of non-purchase sessions are much shorter than sessions that resulted in purchases, with the median length falling around 25 clicks. This suggests that our truncated clickstreams used for prediction should not exceed 25 events.
3. Pages and Events
On average, non-purchasing user sessions tend to have a smaller number of unique pages visited compared to user sessions that result in successful purchases, regardless of the clickstream cutoff length. Therefore, the variety of unique pages visited may be correlated with purchase decisions.
When looking at the first 25 clicks of each user session, sessions without purchases typically consist of 2-3 unique pages, while sessions with purchases consist of up to 4-5 unique pages on average.
4. Highly Correlated Events
.png)
.png)
We plotted the transition probabilities between click interactions to get a sense of user navigation patterns across the website. The resulting heatmap helped us understand that click events such as "purchase" and "exit" may cause data leakage and should be removed from clickstreams, as their transition probabilities in both classes are noticeably different.
1. Undersampling
Given the highly imbalanced dataset, we downsampled our dataset to achieve a 5:4 ratio of Non-Purchase labels to Purchase labels, avoiding false convergence to the majority class during training.
2. Removing Outliers
Sessions with either clickstreams length that are too short or too long with be removed as outliers. Clickstreams shorter than 2 clicks are excluded as well as it doesn't provide enough information for training.
3. Feature Engineering
Sessionizing: Click logs at different timestamps are organized into event sequences and grouped by sessions to prepare for modeling sequential data. To accomplish this sessionizing process, a preprocessing function from the Python library Markov Click was used.

Truncating Clickstreams at Different Cutoff Lengths: We will be experimenting with models training on different cutoff lengths ranging from 2 to 25 clicks. Therefore, clickstreams are truncated at different cutoff lengths prior to training each model.
4. Preventing Data Leakage
Some events/pages within click paths such as “Checkout Confirmation” or “Purchase” are strongly related to purchasing outcomes. Therefore, in order to prevent these events from “leaking” our labels, we excluded these events to ensure that our models predict purchase intent based only on normal click paths..

Model Selection
This project explored three different methods for predicting purchase intent. Two of them are sequence-based methods trained on click sequences, while the third is feature-based trained on click frequencies.
1. Sequence Discrimination with Markov Chains
In this project, we implemented a sequence discrimination measure proposed by Durbin, R. and Miguéis, V. L. that can be used in the context of predicting customer actions. They assume that sequences in each class (e.g. purchase and non-purchase) come from a specific Markov process for each class, and that we can calculate the likelihood of an observing sequence stemming from either of the classes.
To calculate the likelihood of a sequence, we first create Markov transition probability matrices for each class:

The log odds of transitioning from one state to the other can thus be calculated based on the transition matrices using:

We then calculate the odds of an observing sequence originating from either a purchase class or non-puchase class based on transition probabilities of the two different classes:

In this case, a positive log odds ratio means that the provided sequence is more likely to originate from the buyers class, while a negative value means the opposite.
2. Sequence Classification with LSTM
A common method used in the field of NLP to classify text sequences is the LSTM network, which is a type of RNN that has the advantage of learning longer patterns and forgets/remembers data selectively. In this project, we treated each clickstream sequence as sentences to feed our data into the LSTM. Since click paths for each session in our dataset come in different lengths, each sequence is transformed into a “padded sequence” before passing in as training inputs.

3. Feature-based Standard Classification
The non-sequential features extracted for training standard classification are the click frequencies that are present in a sequence. Similar to storing term frequencies using Bag of Words in NLP, we transform our data into feature vectors where each event represents a single feature. Standard classifiers such as Random Forest and SVM were implemented to train on these features.

1. Experimentation & Evaluation
Aside from comparing across three methods proposed above, we also experimented with different training data combinations for each algorithm:
• Clickstream input data with different session length cutoffs, ranging from 2 to 25 clicks
• Different types of interaction levels – click paths on the page level, event level, and category level.


Overall, sequence classification using LSTM yielded the best performances at an earlier stage (5 to 15 clicks) of a user session. After around 15 clicks, other algorithms such as Markov Chain and Random Forest starts to outperform LSTM. However, since our goal is to predict purchase intent as early in a user's session as possible, the LSTM model would be the best given its accuracy and stability at an early prediction stage.
2. Feature Importance
While the sequential models overall performed better in terms of early stage prediction, they have limited interpretability compared to traditional feature-based classification models. The Random Forest classifier enables us to examine feature importances and identify the pages/events that have a strong impact on classification results. As a result, the "Checkout Your Information," "Home," and "Men's/Unisex | Apparel" pages were the top 3 pages that influenced our feature-based models, while "Begin Checkout", "View Promotion", and "View Item" were the top 3 events with the most impact
.png)
1. At which point of user's click paths should we target them with promotions? In other words, what is the minimum length of clickstream sequence required to make acceptable predictions?
Based on our best models (LSTM), we found that both the F1 score and AUC starts to increase less drastically around the 6th sequence length, and stabilizes around the 10th sequence length, with a F1 score up to 0.73 and AUC up to 0.80. This suggests that a clickstream sequence length of at least 6 click logs is required for accurate predictions, with 10 or more providing even greater stability.
.png)
2. Are sequential models or feature-based classification models better at predicting customer purchase intent?
Despite the interpretability advantage of feature-based models, the sequential models' superior performance in detecting early stage user intent makes them a more suitable choice for our project goal. However, we acknowledge the importance of interpretability in the context of e-commerce clickstreams.
3. How does the level of interaction (page-level, event-level, category-level) affect prediction performances?
We utilized ANOVA to test whether the performance of models trained on different levels of interaction differed significantly from one another. The results of the test showed that the performances of the three types of click interaction were statistically different. As such, we can further conclude that the LSTM models trained on page-level interactions yielded the best performance out of all the models. However, on average, models trained on the event-level resulted in the highest scores.
